Key Design Choices
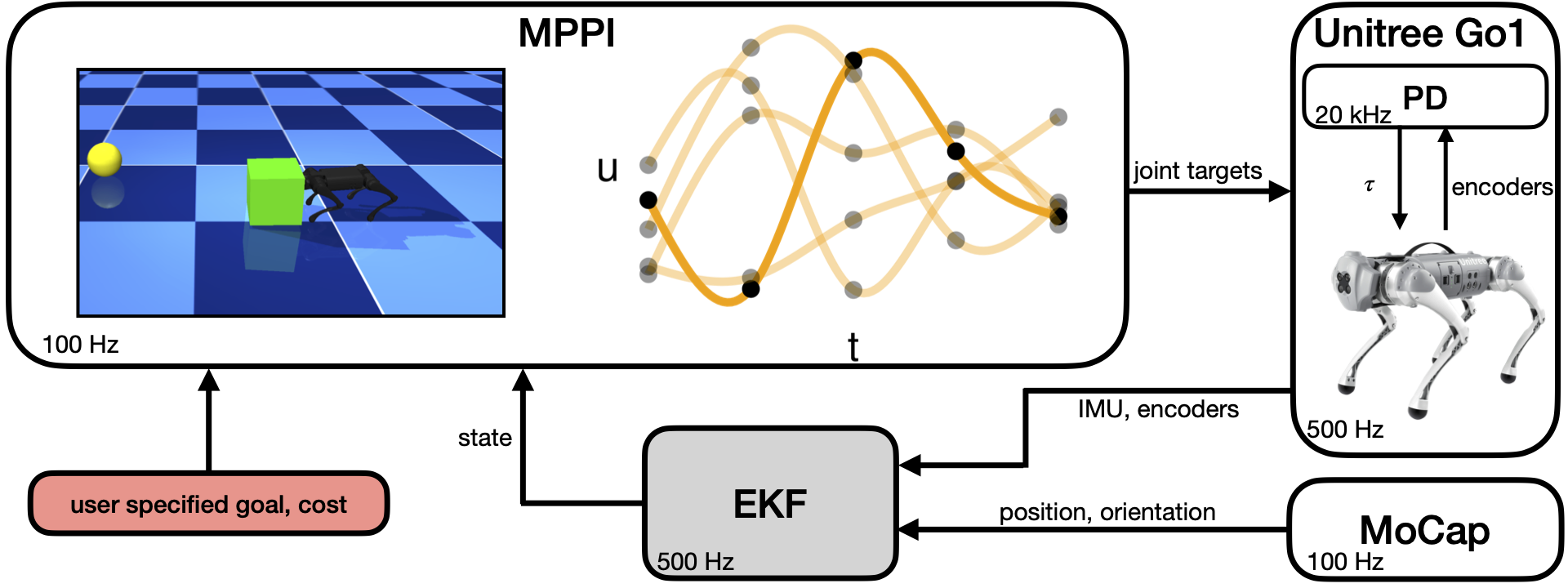
We present the first successful deployment of a whole-body sampling-based MPC system on a real-world quadruped robot. Our approach enables real-time, contact-rich locomotion and manipulation using a single control policy derived from Model-Predictive Path Integral (MPPI) control. Demonstrations include box pushing, box climbing, and robust walking over rough terrain.
Model-Predictive Path Integral (MPPI) control is a gradient-free, sampling-based algorithm widely used in real-time control of complex systems. MPPI samples \( N \) control trajectories from a multivariate Gaussian distribution \( u_t \sim \mathcal{N}(\mu_t, \Sigma_t) \), where \( \mu_t \) is the mean control input at time \( t \), and \( \Sigma_t \) is the covariance matrix.
For each sampled trajectory, the system is simulated forward to compute a corresponding state sequence, and a cumulative cost \( \mathcal{L}_n \) is computed for each trajectory. The weights of each trajectory are computed based on their min-max normalized cost:
\[ \omega_n = \frac{\exp\!\left(-\frac{\mathcal{L}_n - \mathcal{L}_{\min}}{\lambda\,(\mathcal{L}_{\max} - \mathcal{L}_{\min})}\right)}{\sum_{n=1}^{N} \exp\!\left(-\frac{\mathcal{L}_n - \mathcal{L}_{\min}}{\lambda\,(\mathcal{L}_{\max} - \mathcal{L}_{\min})}\right)} \]
The updated control input is then computed as the weighted average of the samples:
\[ \mu_t = \sum_{n=1}^{N} \omega_n u_{n,t} \]
where \( \mathcal{L}_n \) is the cost of the \( n \)-th trajectory, \( \omega_n \) is the corresponding weight, and \( \lambda \) is a temperature parameter that controls the sensitivity of the weighting to cost differences. Smaller \( \lambda \) makes the controller more selective to low-cost trajectories, while larger \( \lambda \) smooths the contribution of all samples.
This process is applied in a receding horizon fashion, making MPPI suitable for real-time applications in systems with contact dynamics or high-dimensional state spaces.
This paper presents a system for enabling real-time synthesis of whole-body locomotion and manipulation policies for real-world legged robots. Motivated by recent advancements in robot simulation, we leverage the efficient parallelization capabilities of the MuJoCo simulator to achieve fast sampling over the robot state and action trajectories. Our results show surprisingly effective real-world locomotion and manipulation capabilities with a very simple control strategy. We demonstrate our approach on several hardware and simulation experiments: robust locomotion over flat and uneven terrains, climbing over a box whose height is comparable to the robot, and pushing a box to a goal position. To our knowledge, this is the first successful deployment of whole-body sampling-based MPC on real-world legged robot hardware.


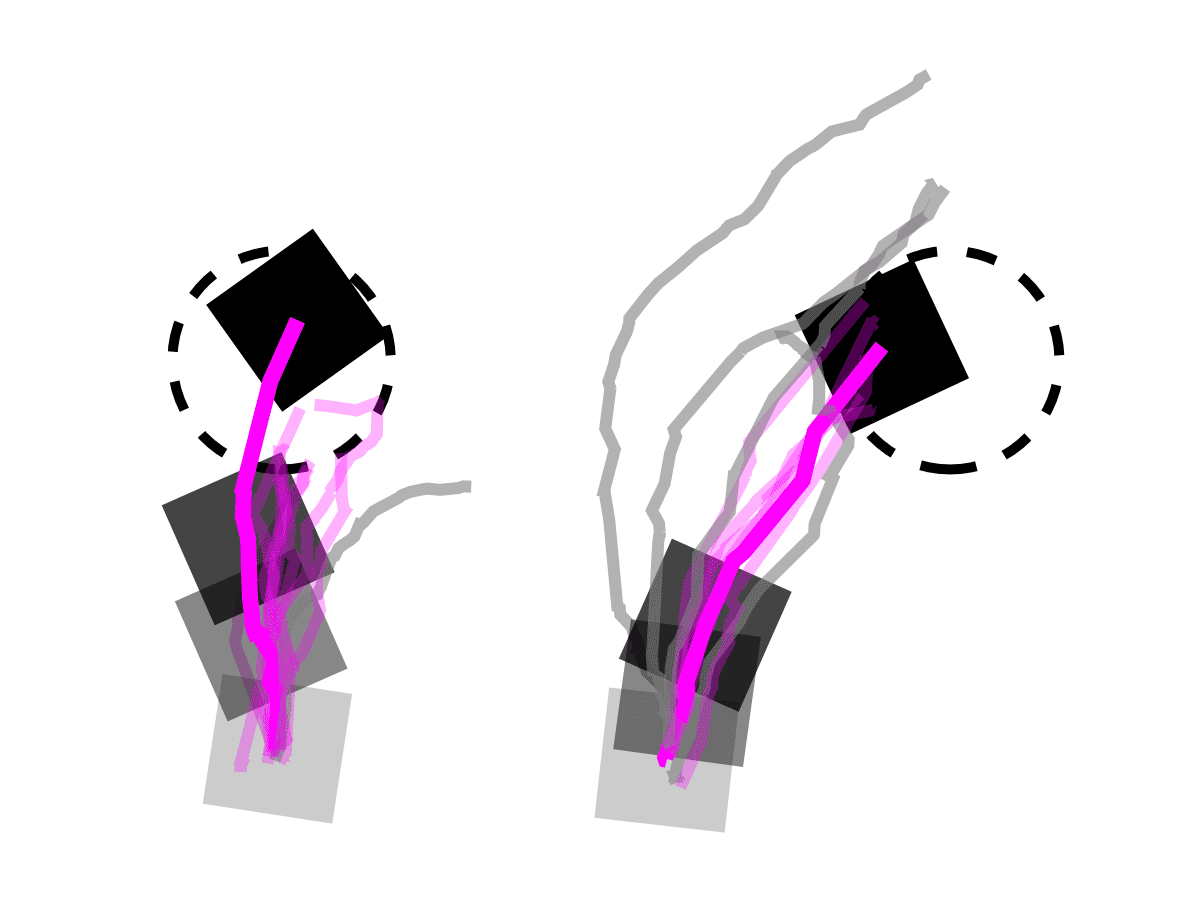
@inproceedings{alvarez2025real,
title={Real-time whole-body control of legged robots with model-predictive path integral control},
author={Alvarez-Padilla, Juan and Zhang, John Z and Kwok, Sofia and Dolan, John M and Manchester, Zachary},
booktitle={2025 IEEE International Conference on Robotics and Automation (ICRA)},
pages={14721--14727},
year={2025},
organization={IEEE},
doi={10.1109/ICRA55743.2025.11128271}
}